2026-07-03
LLM Cost Governance for a Team of Coding Agents
I gave my team Claude Code, Codex, and Kimi. A month later I opened four separate billing pages and still couldn't answer three basic questions: who spent what, on which models, and whether anyone was even still using the tools after the first-week excitement wore off.
Every provider has its own billing page, and none of them line up with my teams and users. So I built a small, self-hostable reference implementation that puts one gateway in front of everything.
Repo (MIT): github.com/0xkaz/llm-governance-dashboard
One Gateway in Front of Everything
Coding agents (Codex / Claude Code / Kimi)
| per-user key, base_url = the proxy
v
LiteLLM proxy -- model name picks the upstream --> OpenAI / Anthropic / OpenRouter / Kimi
| logs every request (callback)
v
BigQuery --> FastAPI dashboard (cost, budgets, adoption)- LiteLLM is the gateway: one OpenAI/Anthropic-compatible endpoint for every provider, with per-user virtual keys and budgets.
- A callback streams every request into BigQuery — cost, tokens, latency, team, user, model.
- A small FastAPI app renders the dashboard server-side (no JS build), plus budget alerts to Slack/email and self-service key issue/revoke.
Everything runs on your laptop via Docker. I verified the whole path on real GCP — proxy on :4010, dashboard on :8010, rows landing in a partitioned BigQuery table.
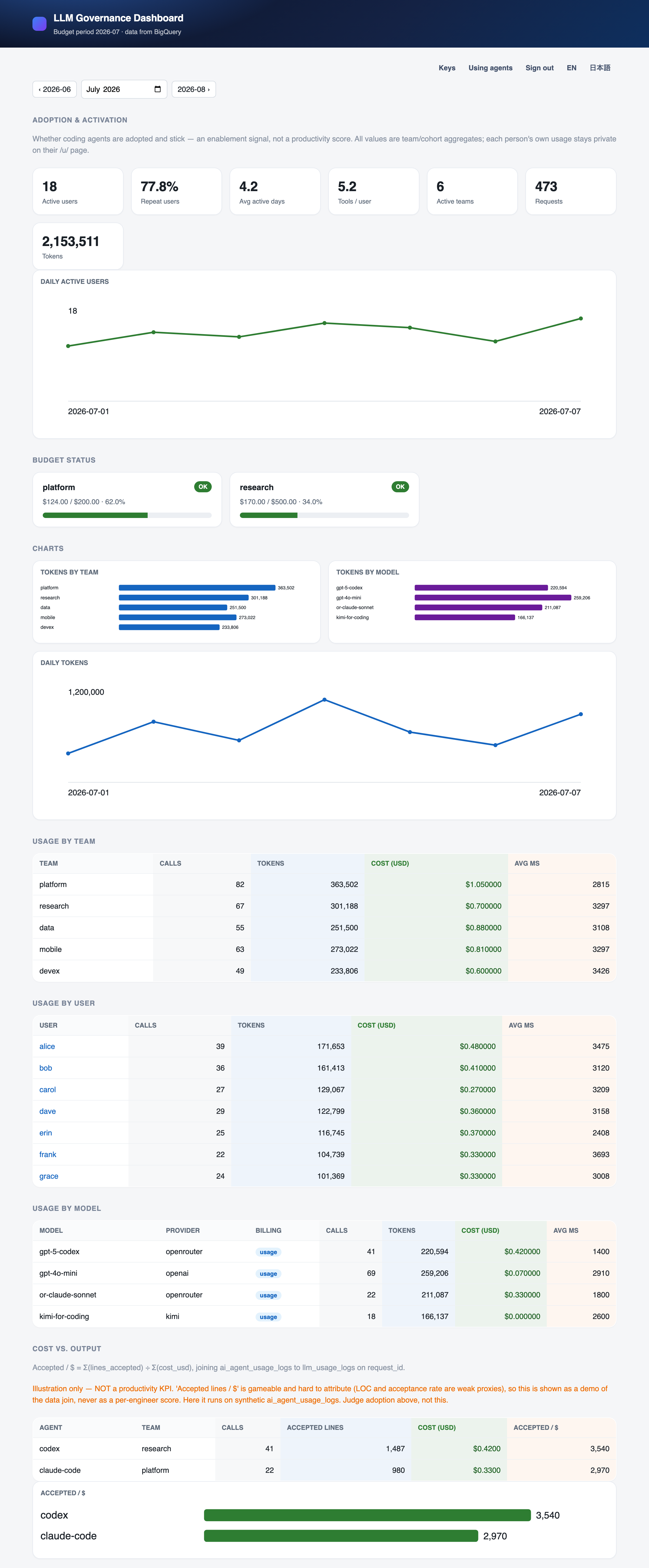
The dashboard on synthetic data — adoption tiles up top, budget status, then cost by team, user, and model. The "Cost vs. Output" panel at the bottom is labeled illustration-only on purpose.
Cost Governance, and the More Interesting Half
Cost governance is the obvious half: spend and latency by user, team, and model; budget alerts at 80% and 100%; virtual keys people issue and revoke themselves, so no one touches the master key.
Adoption trackingis the half I care about more. Is the team actually using the agents, and does it stick? I track weekly-active rate, repeat usage, and how many different tools each person reaches for. Roll-ups are aggregated by team; individual usage stays on each person's own page.
I deliberately track adoption, not a per-developer output number. Usage that sticks is a signal you can act on. A lines-per-engineer leaderboard is one people just game — and every proxy for "productivity" I could log (accepted lines, tokens burned) is either gameable or actively harmful once someone is scored on it.
Streaming Hides the Cost
This one cost me an afternoon. Providers often omit token usage on streamed responses, so the gateway's own per-key spend under-counts — sometimes down to $0 for a request that clearly cost money.
Two fixes. I inject stream_options.include_usage=true at the proxy so usage comes back even when streaming, and I backfill cost from tokens into BigQuery so the dashboard is accurate regardless. The lesson that stuck: treat the warehouse as the source of truth for cost, and the gateway's hard budget-block as best-effort. They will disagree, and that's fine once you know which one to trust for which job.
Subscription CLIs Bypass the Gateway
A ChatGPT-logged-in Codex, the claude.ai app, and Moonshot's Kimi CLI talk to their vendor directly. In that mode nothing is logged.
But this is a routing problem, not a measurement limit. Anything that goes through the gateway is measured — including subscription and flat-rate usage (tokens and latency are recorded; cost just shows 0, labeled as billing_type=subscription). The fix is to force traffic through the proxy — API-key auth, or a generic OpenAI-compatible client for Kimi — and block direct egress. That's org policy, not a tool limitation. Worth being honest about both halves.
Per-User Attribution Needs Virtual Keys
With the raw master key, everything shows up as one user. The dashboard is useless. Hand each person a scoped virtual key — issued and revoked through the proxy — and suddenly user_id and team land on every row in BigQuery. That single change is what turns a pile of request logs into something you can actually make decisions from.
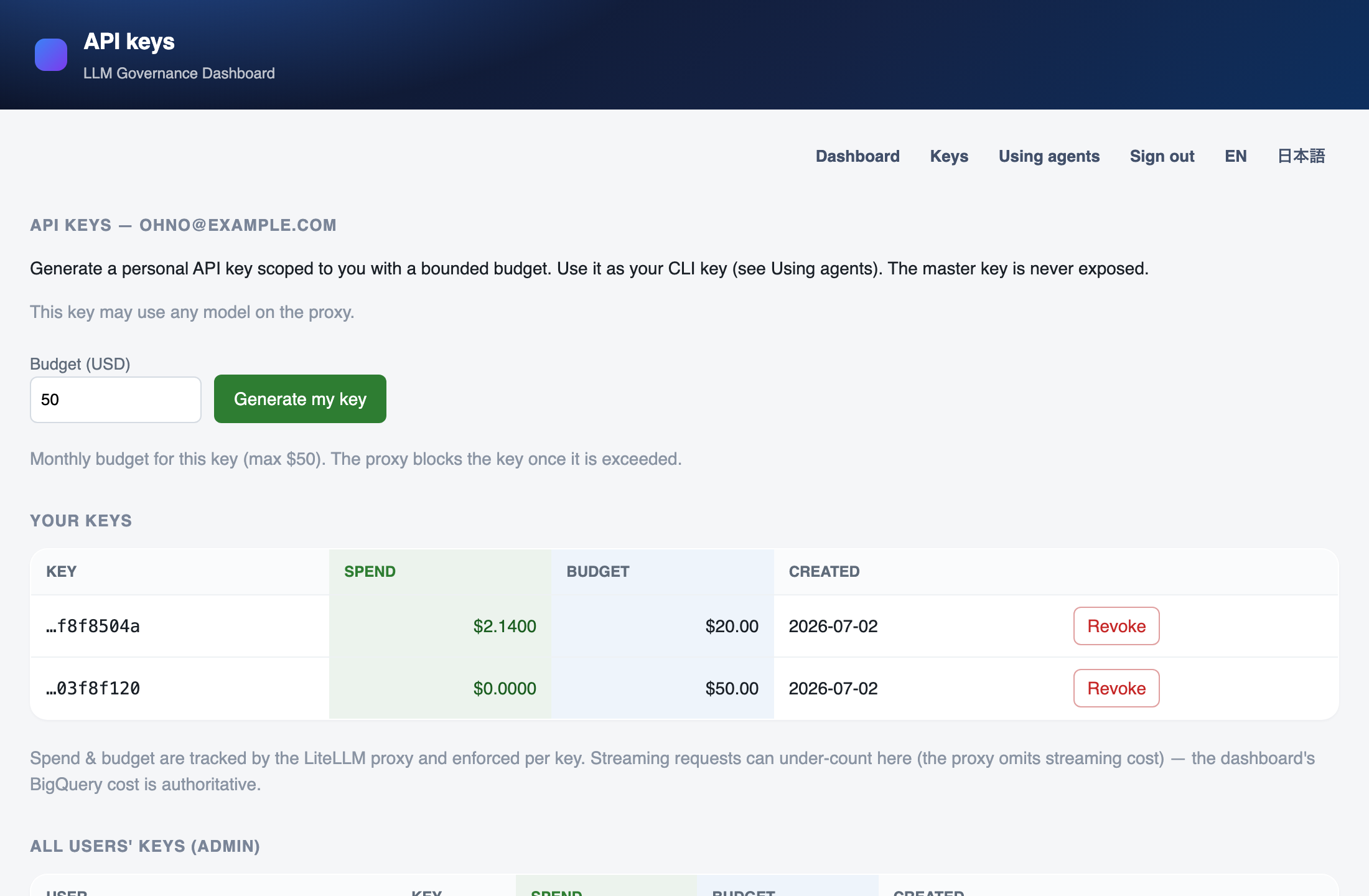
Each person issues and revokes their own scoped key with a bounded budget — the master key is never exposed. Note the caption: the proxy can under-count streaming, so BigQuery cost is authoritative.
What It Is (and Isn't)
It's a demo / reference implementation, not a production product. No TLS, single node, no multi-tenant hardening. BigQuery and Looker are swappable for any warehouse or BI tool — the real requirement is just one place that holds every per-request log.
It also leans different from the observability tools people will reach for first. Helicone, Langfuse, and Portkey are excellent at tracing and debugging calls. This is deliberately thinner and pointed at a different question: governance and adoption— who's allowed to spend what, and is the team actually using the tools. Treat it as complementary, not a competitor.
If that fits how you'd approach the problem, fork it. I'm curious how others are governing AI coding spend across a team — gateway-first like this, or something else entirely?
Related: Building with Claude Code + Telegram.